The short answer
Preliminary observations appear within the first handful of similar trades. Patterns with enough confidence to act on emerge after enough similar trades accumulate to overcome small-sample noise — typically a few dozen trades on a given dimension. Robust patterns, the kind worth treating as a load-bearing input to your pre-trade routine, accumulate as your history grows toward the hundreds of trades.
These ranges are not arbitrary. They are bounded by classical statistical inference operating on small samples. The next sections explain the math, then the practical implications.
Why sample size matters more than any individual trade
A trader who has logged a small handful of trades and sees a high win rate on one slice is looking at a number whose true value could plausibly sit across a wide range. The point estimate is what a spreadsheet would surface. The honest range — wider when the sample is small, narrower when the sample is robust — is what the inference actually warrants.
The width of that range is not a flaw in the math; it is the math telling the truth about how much evidence supports the claim. A trader who acts on small-sample numbers as if they were precise is being misled — not by the data, but by ignoring the uncertainty around it. The job of a pattern engine is to make the uncertainty visible, not to hide it behind a confident-looking number.
The four-tier system, and what each tier requires
Kyra's pattern engine uses four tiers that correspond to different stages of statistical confidence:
- Tracking — too few similar trades to draw a real conclusion. The candidate is noted, not claimed.
- Hint — plausible pattern. The confidence range is still wide; treat as preliminary and keep logging.
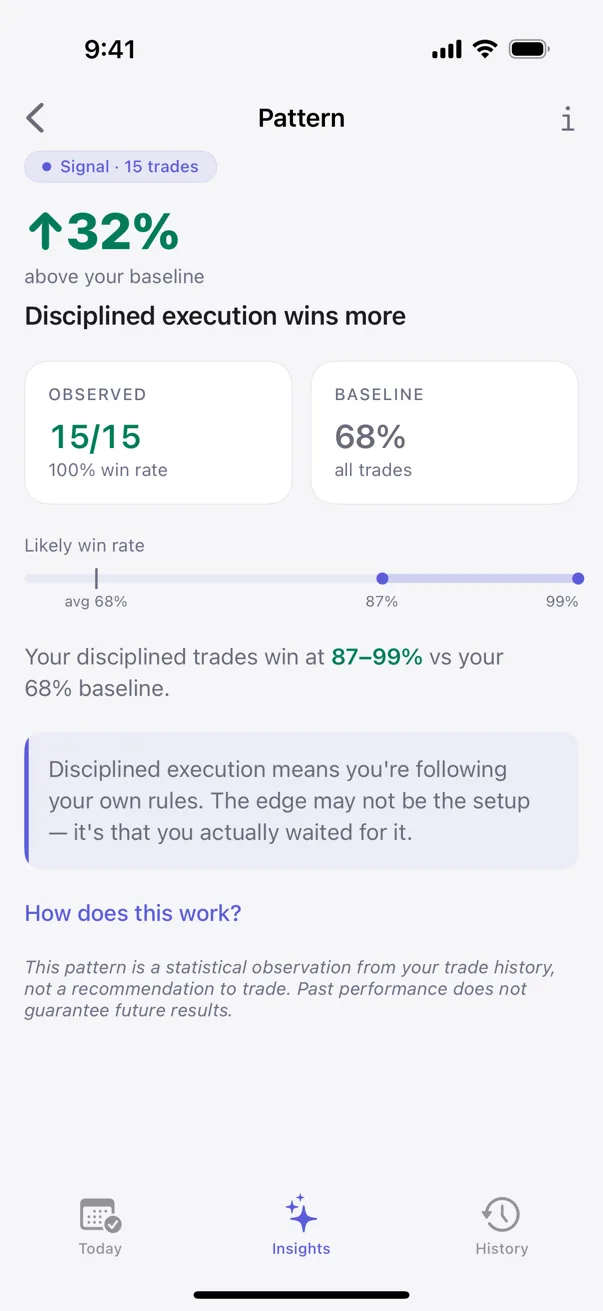
- Signal — meaningful pattern. The confidence range has narrowed. Reasonable to let into the pre-trade checklist.
- Proven — robust pattern. The confidence range is narrow enough to treat as a load-bearing input.
Promotion between tiers is calibrated against published research on how rate estimates stabilize as sample size grows. Schönbrodt and Perugini (2013) quantified how unstable correlation estimates are at small sample sizes and how the instability decays as n grows — that paper is the methodological backbone for why Kyra has tier labels at all. See Research for the full bibliography.
What logging cadence actually looks like
A trader who logs every trade for one month, taking roughly one trade per market day, ends the month with around 20 logged trades. That's enough for the first Hint-tier patterns to begin appearing.
A trader who logs every trade for three months has logged enough that Signal-tier patterns start to appear.
A trader who logs every trade for a year averages around 250 trades. This is the band where multiple Proven-tier patterns coexist and the pre-trade checklist starts surfacing personalized items based on the patterns the engine found.
Logging cadence is the binding constraint. A trader who logs only half their trades — typical for spreadsheet workflows — needs roughly twice the wall-clock time to reach each tier, and the patterns derived from the partial log are biased toward whichever trades were memorable. This is the reason Kyra's Quick P&L mode exists: an under-10-second logging path is the friction floor that makes per-trade logging sustainable enough that the sample sizes accumulate honestly.
Why patterns are personal, and why that takes time
A pattern engine that works against an aggregate dataset can claim things about FOMO trades on day one — there is plenty of evidence in the published literature that directional claims about emotion and trading are true on average. But "on average" is not what a trader is asking. The question is "what does my FOMO look like, and how much is it costing me."
That question can only be answered by the trader's own data. And the trader's own data starts at zero on day one. The engine can borrow strength from priors — Kyra's defaults reflect the published evidence — but personalized confidence ranges narrow only as the trader's history accumulates.
This is why the engine is honest about being quieter early on. A Tracking-tier ghost card early in a trader's history is not the engine being shy. It is the engine refusing to assert what it does not yet know.
What this looks like in the app
The Insights tab in Kyra renders one card per detected pattern, labeled with its tier and its sample size. A typical sequence for a new user:
- Week 1: a small number of Tracking-tier ghost cards. Each names a possible pattern dimension and notes that more trades are required.
- Weeks 2–4: the first Hint-tier patterns appear. The user starts to see directional claims with wide ranges. The pre-trade checklist begins to surface adaptive items, but the items are cautious — the engine is still uncertain.
- Months 2–3: Signal-tier patterns appear. Ranges narrow. The pre-trade checklist gets more pointed because the patterns it derives from are more reliable.
- Month 4+: the first Proven-tier patterns appear in dimensions where the user has enough condition-matching trades. The most reliable patterns become anchor points for the trader's pre-trade routine.
The trajectory is not linear. Some dimensions reach Proven faster than others — depending on how varied the trader's behavior is along each dimension. A trader whose emotional baseline shifts dramatically across trades gets emotion patterns sooner than a trader whose emotional baseline is uniformly calm.
Why the engine resists promotion
A naive engine could surface every cross-tab as a "pattern" at small sample sizes and let the user decide. Kyra refuses to do this — and the refusal is part of the architecture.
The reason is the multiple-comparisons problem. If an engine tests many independent comparisons at once, you expect some apparent patterns purely by chance — even when nothing real is going on. A pattern engine that runs many comparisons faces this problem at scale. Kyra applies multiple-comparisons correction before promoting any pattern between tiers — the math forces the engine to be quieter than a naive run would be, in exchange for the surfaced patterns being mostly real.
The cost: fewer patterns surfaced early. The benefit: when a Signal-tier or Proven-tier pattern appears, it is unusually unlikely to be noise. The math is doing the work that an honest trader would otherwise have to do by squinting at their own spreadsheet.
What this means for a trader deciding to start
The honest framing: pattern claims at low sample sizes are interesting but not yet actionable. Patterns that reach Signal- or Proven-tier are worth letting into your pre-trade routine. The first month of logging is mostly about establishing the schema and the cadence; the second and third months are when the engine starts to earn its keep.
Two practical implications:
- Don't grade Kyra on week one. The patterns are honest about being uncertain that early. Judging the engine at low sample sizes is judging the trader's small dataset, not the engine's quality.
- Lower the logging friction to compound faster. Quick P&L mode exists for exactly this reason: a sustained under-10-second logging cadence gets you to Signal-tier patterns in weeks instead of months.
The pattern engine is built to grow with the trader's history. The architecture, the math, and the four-tier system all assume that the trader is in for the long game. For traders not in for the long game, a spreadsheet is probably the better tool.
For the underlying math (Bayesian inference, Fisher's exact test, multiple-comparisons correction), see The math behind Kyra. For the published research that grounds the tier-promotion approach, see Research. For the operational specifics of how the engine surfaces patterns in-app, see Pattern detection.