Two very different things get called "AI"
The label "AI" now sits on top of two technologies that behave almost oppositely. One generates — a language model reads your journal text and produces fluent prose: "I notice you tend to overtrade on Mondays after a Friday loss." The other tests — a statistical engine takes your logged outcomes, checks a candidate pattern against what random chance would produce, and reports only what survives, with a sample size attached.
Both are "AI" in the marketing sense. For a trading journal — a tool whose entire job is to tell you something true about yourself — they are not interchangeable. One is built to sound right. The other is built to be right, and to admit when it doesn't yet know.
Narrates a pattern
A language model reads your notes and writes a confident sentence about your behavior. Fluent, instant, and indifferent to whether the pattern is real or noise — it has no concept of a sample size.
Tests a pattern
An engine measures your outcomes, checks the pattern against chance, and surfaces it only when the evidence clears a bar — with the number of trades behind it shown every time.
The problem with a journal that narrates
A language model is a fluency machine. Hand it thirty trades in which you happened to lose three Fridays in a row, and it will tell you — smoothly, persuasively — that you struggle on Fridays. It will not tell you that three losses out of a handful of Fridays is exactly what randomness produces, because it never ran that check. It pattern-matches your text to the shape of an insight and writes the insight.
This is the trap behavioral research named decades ago: people — and now the models trained on their writing — treat a small sample as if it were representative of the whole [1]. A run of three feels like a trend. The model inherits the bias and launders it through confident prose. The danger isn't that the narration is always wrong; it's that a true-sounding sentence and a real pattern are indistinguishable from the outside, and the fluent version is the more believable of the two.
A confident narrative feels smarter than a stat card that says "below your baseline, p = 0.03, n = 41." It reads like a coach who knows you. But the feeling is the problem: the more fluent the claim, the less you interrogate it, and a journal exists precisely to be interrogated.
Statistical AI: test before you trust
The alternative isn't "no AI." It's AI that does the boring, honest part first. Before a pattern is shown to you, it's tested against the null hypothesis that nothing is going on — that the result is what chance would have produced anyway. Only patterns that clear that bar surface, and they surface labelled by how much data stands behind them, so a weak early signal is never dressed up as a verdict.
That's a different promise than "our AI found a pattern." It's "this pattern survived a test, and here is exactly how much evidence it has." The math is transparent and checkable — the same spirit as a P&L calculator or a risk/reward calculator, where you can see precisely how the number is produced, rather than a black box that asks you to take its word. How much data it takes before a pattern earns trust is its own question, and the honest answer is more than a narrative ever waits for.
The second AI question: who does the diagnosing?
There's a second, quieter design choice hiding inside most "AI journals," and it matters as much as the first. Many of them ask you to diagnose yourself at the moment you log: Was this a FOMO entry? Was this revenge? Were you overconfident? Then the AI analyzes the labels you applied.
The problem is who's being asked. The trader who just took a loss is the worst available diagnostician of why they took it. Decades of research show that people have remarkably poor access to the real causes of their own behavior — when asked why they did something, they confidently report reasons that demonstrably weren't the cause [2]. Put a "was this revenge?" chip in front of someone mid-tilt and you get one of two failures: they over-label (every loss becomes "revenge") or they skip it and pretend the trade was clean. Either way, the "AI analysis" downstream is computed on data the trader falsified to themselves at entry.
Detected, not self-diagnosed
The fix is to stop asking the question you can't answer. Instead of "was this FOMO?", a journal can collect a neutral input — the state you were in, named plainly: calm, focused, frustrated — and let the statistics tell you what that state actually correlates with across dozens of trades. You don't pre-judge the trade. The engine reads the outcomes and surfaces the pattern, if there is one.
This is the cleaner division of labor. You're a reliable reporter of how you felt; you're an unreliable judge of what that feeling did to your results. So report the feeling and let measurement do the judging. The app detects the pattern; you don't self-diagnose it. What you log should be the raw, honest input — not a verdict you were in no position to issue.
Why this matters more for a journal than a chatbot
If a general chatbot confidently makes something up, you shrug and move on. A trading journal is different, because its output is an input — to which patterns you trust, which setups you keep, how you size, what you try to fix. A confidently-wrong narrative, or a self-falsified label, doesn't just feel nice in the moment; it quietly corrupts the one process meant to find your most expensive habit. The better the prose makes you feel, the more dangerous a wrong claim becomes, because you'll act on it.
An honest journal is willing to tell you it doesn't know yet. "Not enough data" is a feature, not a failure — it's the difference between a tool that respects the evidence and one that performs certainty. A pattern you can trust is one that was tested and earned its place, not one that was generated because you asked.
Privacy is part of the AI question too
There's a final difference that's easy to miss. Generative narration generally means your journal text — your emotions, your losses, your strategy notes, some of the most sensitive data a trader keeps — gets sent to a language model in the cloud to be read. Statistical detection can run entirely on your device, because testing a pattern against chance doesn't require a server. The choice between the two kinds of AI is also a choice about where your trading data goes.
How Kyra approaches it
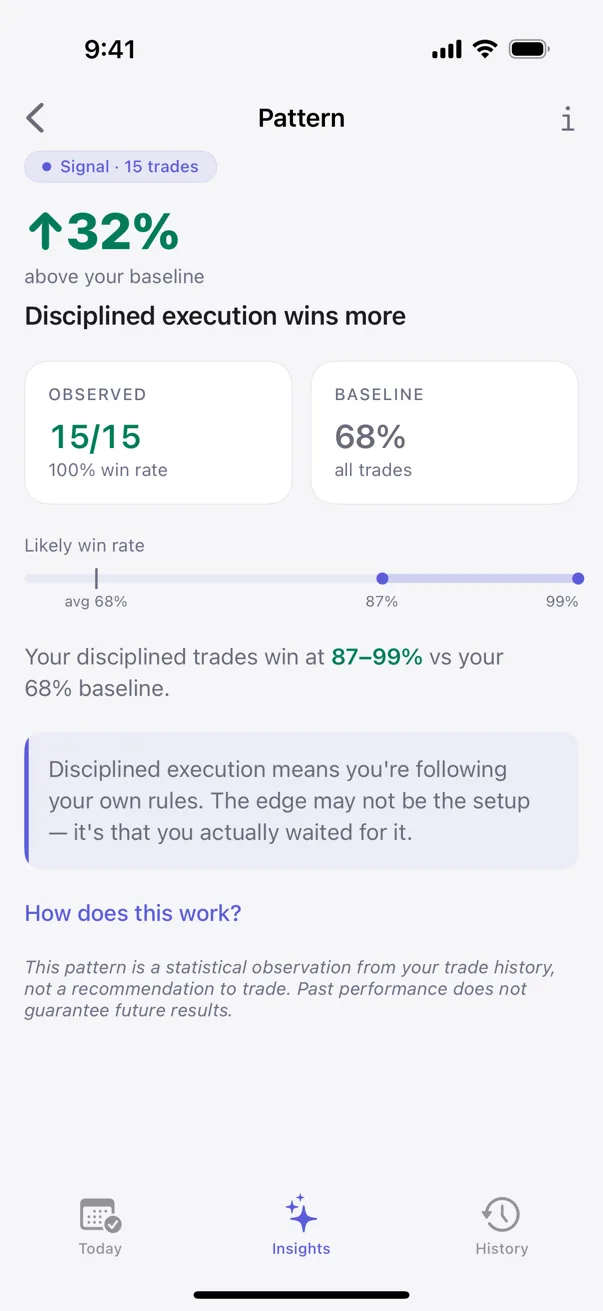
Kyra is built on the second kind of AI. Its intelligence is a statistical engine, not a narrator: it bins your outcomes by the factors you log — emotion, setup, execution, time of day, direction — and surfaces a pattern only when it clears a test against chance. It labels every pattern by how much data stands behind it — Tracking, Hint, Signal, or Proven — so a claim earns trust only as the evidence accumulates. Every pattern surface carries its sample size and a uncertainty range. There is no chatbot guessing at your notes; there is a measurement, with the number of trades behind it shown.
It also asks for neutral inputs and does the diagnosing itself. You record the state you were in; the engine tells you what that state is doing to your win rate. And because testing a pattern doesn't need a server, all of it runs on-device — no accounts, no upload. The trader's data stays the trader's data. That's the version of "AI trading journal" worth having: tested, gated, honest about uncertainty, and private by construction.
Sources
- Tversky, A., & Kahneman, D. (1971). Belief in the law of small numbers. Psychological Bulletin, 76(2), 105–110.
- Nisbett, R. E., & Wilson, T. D. (1977). Telling more than we can know: Verbal reports on mental processes. Psychological Review, 84(3), 231–259.
Educational only. Not financial or trading advice. Behavioral mechanisms described above are observations from the published literature; specific outcomes vary with individual circumstances.